- Qualcomm Launches Snapdragon 4 Gen 2 Mobile Platform
- AMD Launches Ryzen PRO 7000 Series Mobile & Desktop Platform
- Intel Launches Sleek Single-Slot Arc Pro A60 Workstation Graphics Card
- NVIDIA Announces Latest Ada Lovelace Additions: GeForce RTX 4060 Ti & RTX 4060
- Maxon Redshift With AMD Radeon GPU Rendering Support Now Available
Social & RSS Feeds
Latest Videos



Latest News
Lucid HYDRA Engine Multi-GPU Technology
by Rory Buszka on August 25, 2008 in Graphics & Displays
One of the more exciting third-party demonstrations we saw at Intel’s 2008 Developer Forum was by a little-known company called Lucid, who promises highly-efficient multi-GPU performance scaling via their unique “Hydra Engine” technology. We take a look at Hydra Engine, and what it means for ATI’s Crossfire and NVIDIA’s SLI.
Page 2 – HYDRA Architecture Details
What makes Lucid’s current HYDRA implementation different from the other multi-GPU technologies on the market is that it places another stage of hardware processing between the CPU and the GPU. This has raised questions of additional latency, but Lucid assures us that any latency added is inconsequential – the HYDRA 100 SoC handles the decomposition and recomposition of individual frames so quickly that your eye won’t even notice. And indeed, in the demonstration that we witnessed, the system was snappy and responsive, without any perceptible delay.
Let’s take a look at how the HYDRA Engine algorithm and HYDRA 100 system-on-a-chip work together to achieve seamless multi-GPU integration.
The HYDRA 100 ASIC
At present, Lucid’s HYDRA Engine algorithm is tied to the Lucid-designed HYDRA 100 ASIC, whose system-on-a-chip architecture handles the calculations required by the HYDRA Engine completely independent of the host PC. At present, the company has no plans to carry out HYDRA Engine calculations in software on the host machine’s CPU, but it’s not entirely inconceivable that the CPU could be used for this processing in the future. We’ll revisit this notion in a bit, but let’s continue on with our analysis of the current hardware-based implementation.

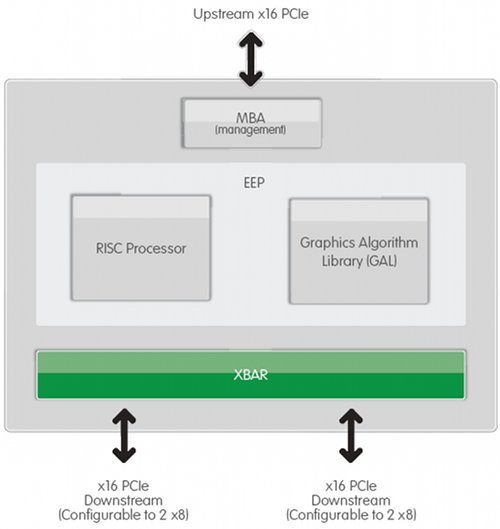
As we mentioned before, the Lucid-designed HYDRA 100 SoC incorporates an embedded RISC processor running at 225MHz, and a graphics algorithm library. It also contains 32 kilobytes (yes, kilobytes) of memory and both a 16-lane upstream and dual-16-lane downstream (reconfigurable to quad-8-lane) PCI Express switch. That means that from a single HYDRA 100, quad-card configurations are possible, which is about as many GPUs as you’d want to run in an ordinary desktop PC. However, Lucid informed us that the HYDRA ASIC architecture is highly scalable, which means you could see any combination of PCI-E input and output lanes.
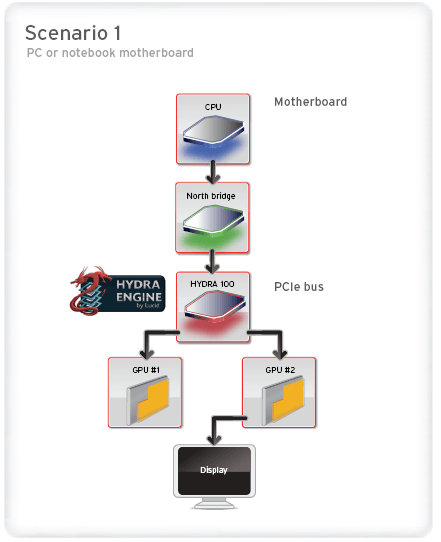
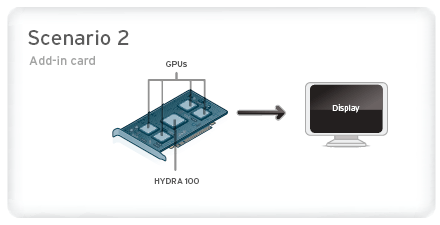
Lucid suggests two possible scenarios for an implementation of HYDRA silicon – first as an additional chip on a gaming or workstation PC motherboard, between the northbridge and the PCI express x16 slots, and alternately as a central chip on a multi-GPU add-in board. On current models of multi-GPU add-in boards like AMD’s ATI Radeon HD 4870 X2, a PCI Express bridge (sourced from a company like PLX) is used to split the sixteen incoming lanes of traffic into a pair of 8-lane ports – with Crossfire functionality continuing to be handled in software. But swap out that PCI Express bridge for a Lucid HYDRA 100, and suddenly you’ve got more efficient performance scaling, and support for up to four GPUs on a single card.
So, how do the multiple GPUs connected to a HYDRA ASIC relate to the host system? The Lucid HYDRA Engine is capable of bringing together dissimilar cards to work on rendering tasks – however, there is one limitation: All GPUs must be able to share the same software driver. That means you can forget mixing and matching cards with ATI and NVIDIA GPUs in the same HYDRA configuration. Cards from both makers can theoretically be present in the same system, however – you could have a HYDRA array of ATI Radeon HD 4870s handling the video rendering, with a low-end NVIDIA GeForce 8600GT handling PhysX acceleration, for example.
So as best we can tell, the Lucid HYDRA 100 ASIC appears to the host system as a single graphics processor of whatever GPU family is arrayed together in the HYDRA configuration. The benefit of this is that you won’t need ATI or NVIDIA to pony up special drivers for their video cards – you won’t even need to run in SLI or CrossfireX mode.
Next, let’s look at the nuts and bolts of the Lucid HYDRA Engine algorithm.
The HYDRA Engine Algorithm
We already touched on what the HYDRA Engine algorithm basically ‘does’ on the preceding page of this article. The HYDRA Engine balances the load between multiple GPUs by ‘decompositing’ the GPU rendering tasks – the digital bits and pieces that tell a video card what to render – and then ‘recompositing’ the results into a complete rendered image.
While we can’t give specific performance numbers, since the private demonstration we were given didn’t include a benchmarking session, we did observe a consistent 58-60 fps in Crysis on a pair of NVIDIA GeForce 9800GTX cards, with all the game’s graphics settings pegged at ‘high’ under DirectX 9. So the HYDRA Engine works, delivering nearly double the single-card performance figures – and we’ve seen it with our own eyes.

The HYDRA Engine load-distribution algorithm is by far the most complex that we’ve seen, which begins to give us some idea of why Lucid seems so dead-set on keeping the algorithm’s implementation based in hardware – their hardware, to be precise. It brings together a variety of historical data, and dynamically balances the processing load based on individual tasks, not complete frametimes.
First, the algorithm collects data on the time required by each subordinate GPU to accomplish a task with a certain complexity level, and stores this data in a small repository of data. Then the algorithm looks at the types of tasks being requested by the 3D application, and decides which of the connected graphics cards would be best-suited to each task.
From there, the HYDRA Engine algorithm dispatches the individual tasks to each of the connected cards, then recomposites the image using its own onboard composition engine and returns that image to one of the video cards, to be displayed on the output monitor. The HYDRA Engine also handles other optimizations, such as occlusion-culling, in its own hardware, freeing the video card from any extraneous processing.

Support our efforts! With ad revenue at an all-time low for written websites, we're relying more than ever on reader support to help us continue putting so much effort into this type of content. You can support us by becoming a Patron, or by using our Amazon shopping affiliate links listed through our articles. Thanks for your support!