- Qualcomm Launches Snapdragon 4 Gen 2 Mobile Platform
- AMD Launches Ryzen PRO 7000 Series Mobile & Desktop Platform
- Intel Launches Sleek Single-Slot Arc Pro A60 Workstation Graphics Card
- NVIDIA Announces Latest Ada Lovelace Additions: GeForce RTX 4060 Ti & RTX 4060
- Maxon Redshift With AMD Radeon GPU Rendering Support Now Available
Social & RSS Feeds
Latest Videos



Latest News
SysAdmin Corner: Demystifying RAID

by Brett Thomas on September 24, 2012 in Editorials & Interviews, Storage
Interested in RAID, but not sure which option is right for you? The goal of this article is to clear up any confusion you may have. We discuss what RAID is, what it isn’t, potential dangers, differences between popular RAID levels and last but not least, what you need to get yourself up and running with your very own RAID.
Page 2 – RAID Zero, One, Five, Six… Ten
Sure, it looks like a screwy numbering system – the truth is, there are a lot more numbers, but these are the ones you need to be concerned with. The lower the number, the less disks it actually takes to build a working array – which means that higher numbers will be more “balanced” than lower numbers, which are more extreme.
RAID 1
Ah, the good ol’ workhorse. It may seem like we’re going out of order, but we’ll get to RAID 0 in a minute. See, RAID 1 is what puts the R in RAID – perfect redundancy. It functions by taking a minimum of two disks, and acting like it only has one, making a perfect mirror of the first disk on each subsequent disk for every write operation.
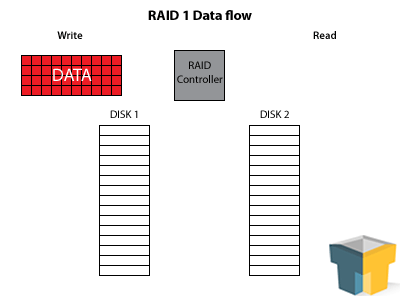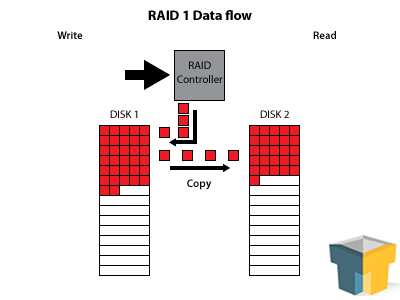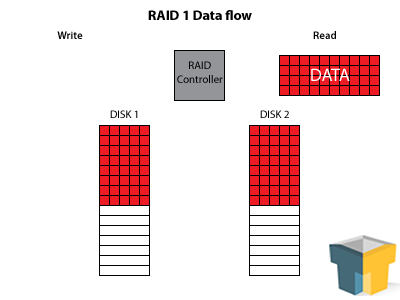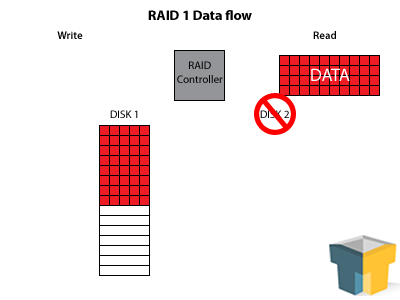
RAID 1 increases your read speeds by quite a bit – there are two (or more) drives to pull the information from, so speeds essentially double, triple, etc. Furthermore, since the data is perfectly duplicated across all of the disks, you can lose every disk in the array except one before you lose your data. So, in a three-disk array, you’ll have 3x the read speed – and you can have two complete hard drive failures before you have to panic.
This redundancy and speed boost makes RAID 1 a winner for your mission-critical data. Your up-time is protected, and with a hot-swappable SATA connection, you can actually switch out bad disks and fix the array “on-the-fly” with very little performance loss. However, every disk you add to the array increases the fault tolerance and read speeds, not the storage capacity – so three 2TB drives still only nets you 2TB of storage, making it a hard sell for the bank account.
RAID 0
This is the speed demon of the group, and also the most dangerous with no fault tolerance. RAID 0 is created by taking a minimum of two disks and “striping” the data between them. This means that each file-system block gets written on a different disk, alternating across all in the array. For instance, if you take a standard NTFS partition (4KB chunk on most drives), then each 4KB of the file will be written on a different disk, allowing you to pull the same data off in less than half the time (for two disks) and more like a quarter of the the time for three disks.
Many people think that it should be “half the time” for two disks and “one third” for three disks, like RAID 1 – but it’s way faster. How come? It’s because each drive only gets its chunk of the data, meaning that the drive heads don’t have to move as far between subsequent reads. In a two disk setup, one drive reads its sector, the next reads its sector, and the first one reads its very next sector – it doesn’t have to pass over the information that the second disk had, as it would in RAID 1.
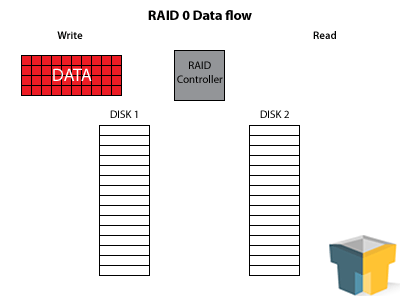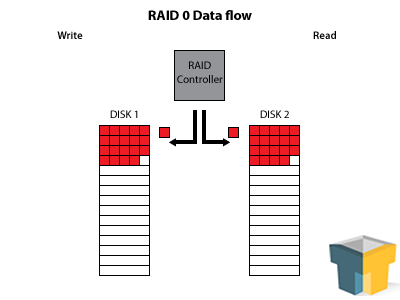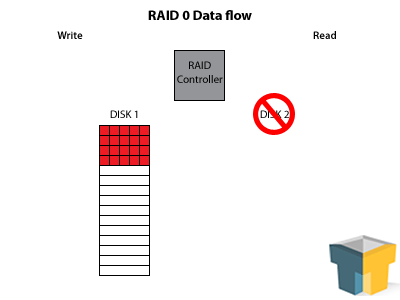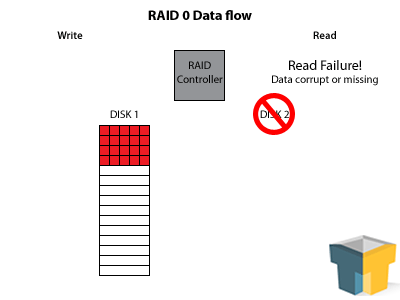
RAID 0 has one other perk – if you use two 2TB drives, you’ll end up with 4TB of usable storage space, because the drives do not have to store any extra information (except a tiny bit of info for the RAID controller).
Before you start thinking this sounds awesome, make sure to read the fine print. Figure that each hard drive has a (I’m pulling a random figure out) 98% likelihood of working correctly. This means that for each drive you add to the system, you decrease the likelihood of the whole array functioning correctly (given the number above, the array’s functional likelihood would be 0.98^X, where X is the number of drives) – a three disk array has a nearly 6% chance of failure at any time. Add to this the fact that the loss of any one drive will destroy all data on the array, and you have a very dangerous choice.
Essentially, use RAID 0 at your own risk for things you don’t mind losing. It’s great for temporary workspace of large files (game installs, etc) that are backed up elsewhere. Do not use for: operating system, inconsistently backed-up data, or mission critical data (even with backups, due to loss of uptime).
RAID 5
RAID 5 is essentially the “perfect RAID” for a low number of disks or storage space. It combines the best of both worlds of RAID 0 and RAID 1 in an interesting blend – using a minimum of three drives, it stripes across all but one drive and uses that last drive as a “parity” drive (think of it as a checksum or error correction). This means that the array has some level of fault tolerance, and some level of RAID 0 read-speed enhancement and space usage. RAID 5 can afford to lose one disk out of the set at any time.
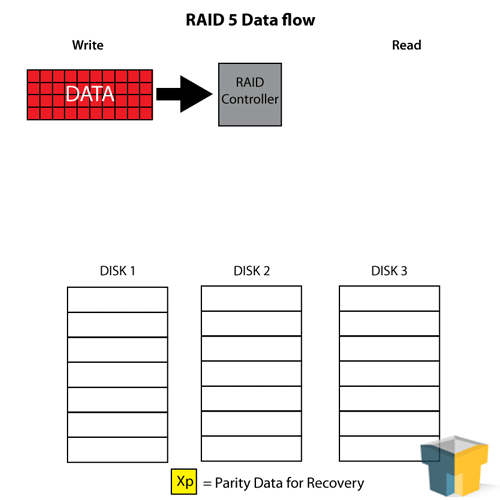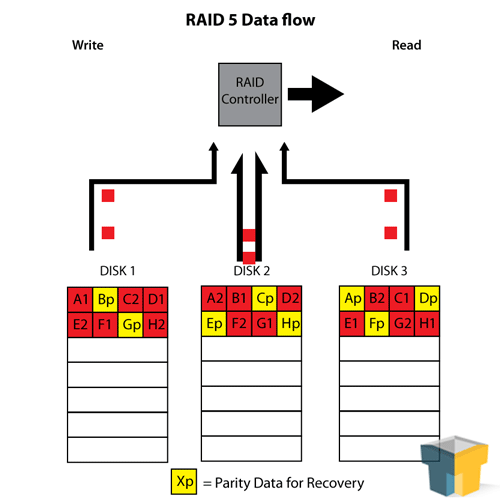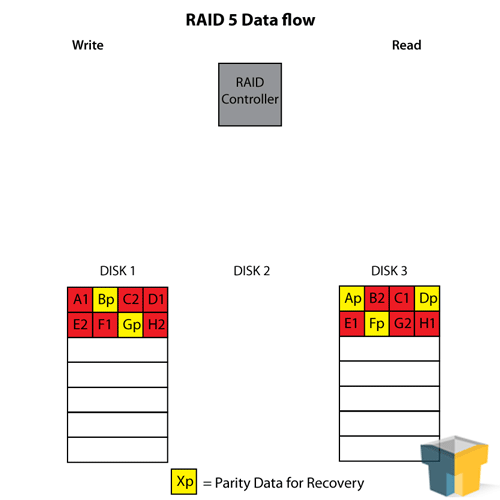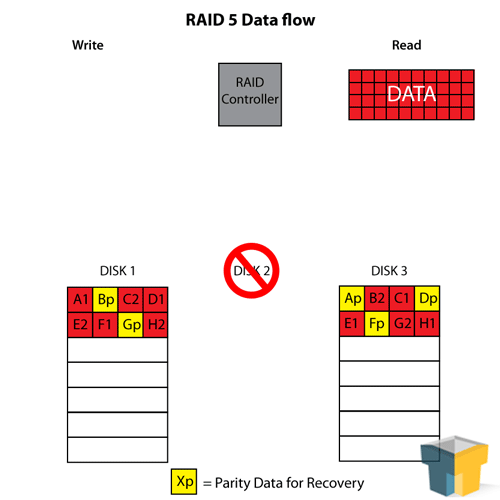
Though we speak of the parity disk in RAID 5 as if it is an independent disk with only parity blocks on it, the reality is that the parity block is striped to a different disk each time – meaning every disk is, in essence, a parity disk for 1/3 to 1/4 of the data on the array. This aids in recovery if a disk fails, as the parity blocks needed for reconstruction can be pulled from more than one other drive, helping the array rebuild faster.
RAID 5 is great for three to four hard disks due to its space maximisation. Three 2TB drives will create a 4TB array with a one-disk fault tolerance, and it can be extended with an extra drive to make a 6TB array with the same tolerance. Since you don’t normally lose multiple hard drives in one go, this makes it perfect for home and small-office server use – assuming you monitor your drives appropriately. Though its rebuild time (particularly for large arrays) when a drive does fail is considerably lengthier and at a larger performance loss than RAID 1, it’s a small price to pay for the benefits and makes the most use of a small budget. It’s also worth noting that RAID 5 suffers from performance loss while writing data, because it needs to calculate the parity block.
RAID 5 has one other important note – it is not wise to use it above four hard drives or an array larger than around 8TB. The limit is mostly due to how much data you can expect a parity block to reconstruct and how efficiently it can be calculated, as the block is essentially a checksum of all of the blocks written to the other drives (for four drives, it’s a hash of three blocks). Of course these numbers are just guidelines, but disregard them at your own risk!
RAID 6
This is a bit of an odd duck – it’s essentially RAID 5 with an extra parity disk. This might sound wasteful, but it’s not – RAID 5 shouldn’t be used with more than about four disks, and RAID 6 increases that to around seven or eight and an array size of around 15TB (when using 2TB disks). Because of the need for two parity disks, RAID 6 requires a minimum of four disks, which makes sense as it’s essentially an extension of RAID 5. It can lose two disks at any time before the array fails.
Since you wouldn’t use it with four disks when you could run RAID 5, it’s safe to think of this as what to do with five or more if you don’t want to go to the big kahuna (discussed next).
RAID 10 and RAID 01, aka 1+0 and 0+1, aka “the big ones”
Arguably the most powerful RAIDs in performance, RAID 10/01 are also the hallmark of gluttony – they are essentially nested arrays, either a striped array of mirrors (RAID 10) or a mirrored array of stripes (RAID 01). In practice there are performance differences between them, but they are both rare enough in home/small office use that I won’t dwell on them long.
Each requires a minimum of four disks, of which half the storage will be lost to the RAID 1 portion. Therefore, disks must be added in pairs. Whether you stripe the mirror or mirror the stripe determines how much rebuilding is necessary when a disk fails (striping the mirrors is better, which is RAID 10). Because every disk on RAID 10 is individually mirrored and RAID 0 has no real limitations on disk numbers or sizes, it is possible to build some truly impressive arrays in both throughput and size with a very, very high fault tolerance (you can lose half of the array, assuming you don’t lose both mirrors of any one disk).
Other RAIDs
Though there are indeed RAID 2, 3, 7 and other non-standard RAIDs, most of these will not come up in practice and are not even well-supported in most home and small-office hardware. RAID 6 is probably the most unusual one that is encountered in smaller environments as it’s not officially supported by most motherboard RAID controllers.

Support our efforts! With ad revenue at an all-time low for written websites, we're relying more than ever on reader support to help us continue putting so much effort into this type of content. You can support us by becoming a Patron, or by using our Amazon shopping affiliate links listed through our articles. Thanks for your support!