- Qualcomm Launches Snapdragon 4 Gen 2 Mobile Platform
- AMD Launches Ryzen PRO 7000 Series Mobile & Desktop Platform
- Intel Launches Sleek Single-Slot Arc Pro A60 Workstation Graphics Card
- NVIDIA Announces Latest Ada Lovelace Additions: GeForce RTX 4060 Ti & RTX 4060
- Maxon Redshift With AMD Radeon GPU Rendering Support Now Available
Social & RSS Feeds
Latest Videos



Latest News
Radeon Pro vs. Quadro: A Fresh Look At Workstation GPU Performance

by Rob Williams on April 30, 2018 in Graphics & Displays
There hasn’t been a great deal of movement on the ProViz side of the graphics card market in recent months, so now seems like a great time to get up to speed on the current performance outlook. Equipped with 12 GPUs, one multi-GPU config, current drivers, and a gauntlet of tests, let’s find out which cards deserve your attention.
Page 6 – Deep-learning: GEMM, Caffe2 ResNet-50 Training
In recent years, deep-learning seemed to come out of nowhere, yet it’s already become one of the most important aspects of our computing. To solve complicated problems, serious hardware is needed, and in many cases, a single GPU is not going to fit the bill.
Whether we’re using our processors to answer complex biology puzzles, find images quicker, or detect someone’s emotion, one of the beauties of deep-learning is that the available frameworks have been built with scalability in mind. Our tests here were run on one or two GPUs, but if we had 1,000, we’d still see expected scaling.
At the moment, only two deep-learning tests are included here (a similar GEMM and FFT test is on the previous page), both of which are built around CUDA. When we’re able to find a real-world deep-learning test that works equally on both AMD and NVIDIA, we’ll explore it. We are in early days for this kind of testing.
General Matrix Multiply (GEMM)
The results below may appear to be simple, but they’re of utmost importance for a lot of deep-learning work. In this case, GEMM (general matrix-to-matrix multiplication) is accelerated through CUDA’s cuBLAS library, enabling huge performance that makes CPUs look truly inept for the same kind of (extremely scalable) workload.
CUDA allows us to exercise GEMM using half-, single-, and double-precision, which means that any GPU supporting FP16 or FP64 are going to see tremendous performance gains. Unfortunately, none of the GPUs we have here support either, so for these results (and the Caffe2 ones, for that matter), I’m including NVIDIA’s own TITAN V results for the sake of being able to deliver a fuller picture. If you’re wondering if it’s inclusion actually matters, take a gander:
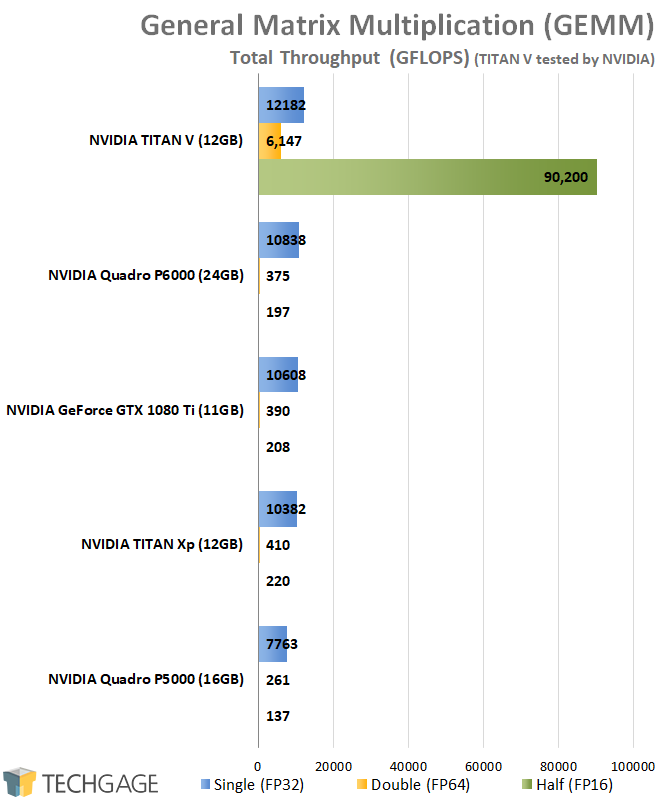
Clearly, any GPU that supports half- or double-precision is going to smash any that don’t, so naturally, the TITAN V, with its uncapped performance, cleans house, while scaling expectedly on the single-precision front. The TITAN V is spec’d for ~25 TFLOPS half-precision, but when the Tensors become engaged, the performance soars through the roof.
It’s worth noting that AMD’s RX Vega offers extremely good half-precision performance as well; about ~20 TFLOPS with the Vega 64, or ~25 TFLOPS with boosting. Given the differences with Tensors, it seems clear that AMD could do well to take a similar route as NVIDIA with its Instinct GPUs.
Caffe2 ResNet-50 Training
We saw above that if a GPU has Tensor cores, the gains in deep-learning are going to be significant. Whereas those results were a simple performance number (despite it being a grueling, long test), this Caffe2 test helps give a better perspective to the gains across one or more GPUs, helping you make the right purchase decision if you have hundreds of thousands, or many millions of images to train with.

Caffe2 ResNet-50 training can use a ton of memory
This particular scenario values the GPU’s memory highly; the larger the memory pool, the larger the batches can be. Using a batch size of 32, which means 32 images are sent to the neural network each iteration, VRAM usage is around ~8.6 GB. This means that our basic test here couldn’t be run on the Quadro P2000, or P4000.
The larger the VRAM, and the computation, the more images can be processed in a batch. If the size is doubled to 64, that increases the VRAM requirement to about ~14.5 GB. Finally, a batch size of 96 requires ~20 GB. With all of that in mind, here are the results:
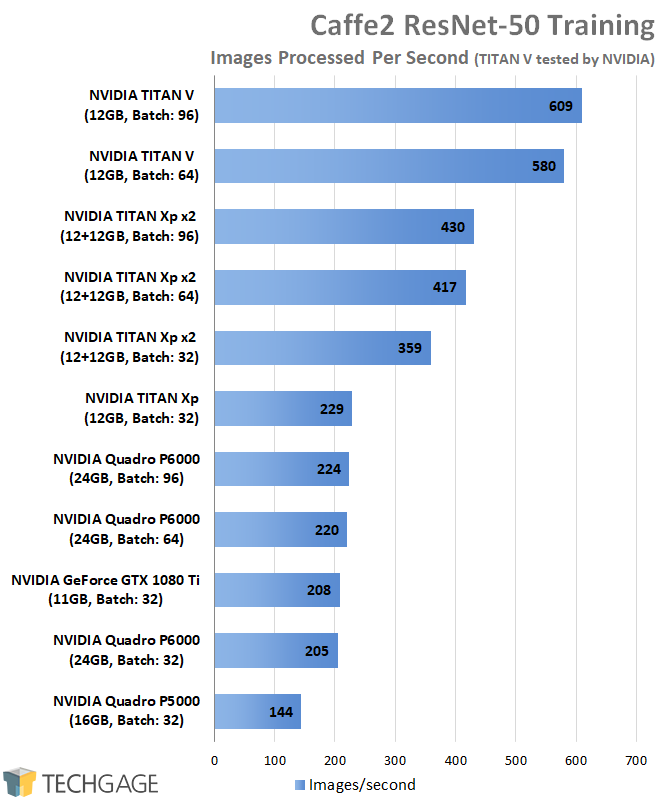
For such a simple chart, there’s an awful lot to talk about here. Let’s start with the P6000, since it has the largest amount of memory (24GB). To my surprise, the P6000 managed to scale just fine all the way up to a batch size of 96, thanks to its many GBs in the VRAM. As noted above, each iteration (32, 64, 96) requires more and more memory, and only the P6000 could handle a batch size of 96 on its own (without available Tensors).
That leads us to the TITAN Xp. As a single card, a batch size of 32 must be used (14.5 GB is too much for the 12GB buffer). However, because this is compute and not graphics, combining two TITAN Xps allows us to use those larger batch sizes – the GPUs simply split up the workload.
Then there’s the TITAN V. Its 12GB buffer escaped its fate as a bottleneck because of the Tensor cores; when the Tensor can work in conjunction with the regular CUDA cores, memory usage is reduced. To which extent, I’m not sure, but a test that’s 20 GB on one GPU and is able to run inside of 12 GB on the TITAN V is an impressive enough takeaway.
Based on these Caffe2 results, it seems likely that a GPU like the Quadro GV100 could greatly outperform the TITAN V thanks to its increased memory (12GB > 32GB).

Support our efforts! With ad revenue at an all-time low for written websites, we're relying more than ever on reader support to help us continue putting so much effort into this type of content. You can support us by becoming a Patron, or by using our Amazon shopping affiliate links listed through our articles. Thanks for your support!

Rob Williams
Rob founded Techgage in 2005 to be an 'Advocate of the consumer', focusing on fair reviews and keeping people apprised of news in the tech world. Catering to both enthusiasts and businesses alike; from desktop gaming to professional workstations, and all the supporting software.


