- Qualcomm Launches Snapdragon 4 Gen 2 Mobile Platform
- AMD Launches Ryzen PRO 7000 Series Mobile & Desktop Platform
- Intel Launches Sleek Single-Slot Arc Pro A60 Workstation Graphics Card
- NVIDIA Announces Latest Ada Lovelace Additions: GeForce RTX 4060 Ti & RTX 4060
- Maxon Redshift With AMD Radeon GPU Rendering Support Now Available
Social & RSS Feeds
Latest Videos



Latest News
NVIDIA Further Optimizes Its Deep-learning Software Platform To Deliver Dramatic Performance Boosts
With a fresh look at workstation graphics performance posted one week ago today, we had many of the usual benchmark suspects, but one page made a sudden introduction: deep-learning. Equipped with CUDA software libraries, we dove into a look at general matrix multiplication (GEMM) performance, as well as performance when churning through images with ResNet-50 training with the Caffe2 framework.
A huge number of deep-learning workloads can be greatly accelerated when half-precision performance is uncapped, but on the vast majority of NVIDIA hardware, that lucrative FP16 is very much throttled. Interestingly, it’s not capped on AMD’s latest Vega graphics cards, even including the gamer-targeted RX Vega 64. Fortunately for NVIDIA, its Tensor cores help set itself even further apart from its immediate competition.
If it didn’t have Tensor cores, the TITAN V would peak at about 30 TFLOPS half-precision, which would still make it the fastest single GPU solution for that purpose on the market. Add Tensors, though, and the performance bursts to about 125 TFLOPS on the V100. In real terms with the TITAN V, we’ve seen a difference of about 300 images processed per second in ResNet-50, versus 600+ with the Tensors.

When I posted the aforementioned performance article last week, 600 img/s seemed like the de facto “best” you could eke from the TITAN V, but NVIDIA has gone ahead and released a number of optimizations that help boost performance even further.
NVIDIA’s ultimate focus here is on the Tesla V100, but the same sorts of gains could be felt by the TITAN V as well, and of course the latest Volta release, the Quadro GV100. If there’s a technical roadblock in place, it’d be tied to the 12GB memory of the TITAN V, but, these latest numbers were all achieved on a 16GB version of the V100, not the 32GB, so that bodes well for TITAN V gains.

A screenshot from our ResNet-50 testing
Nonetheless, with these updates, NVIDIA has improved ResNet-50 training on a Tesla V100 to deliver performance of ~1,075 images per second, a significant lead over the ~600 quoted for the TITAN V last week. With a DGX-1, which sports 8 of these V100s, that performance will jump to ~7,850 images/second, which seems obscenely fast in comparison to the TITAN Xp’s ~230 images/second.
For a bit of an interesting stroll down memory lane, and to give some perspective to things, dual GeForce GTX 580s (circa 2010) would take 6 days to complete ResNet-50 training, whereas today, a 16-GPU DGX-2 can do it in… 18 minutes. Granted, a DGX-2 costs $400,000, versus the maybe $1,000 dual GTX 580s at launch, but as Jensen has repeated at the past couple of GTCs, “The more you buy, the more you save”. In this case, what you save is an enormous amount of time.
Perhaps more significant is that in a mere six months, the DGX-2 became 10x faster at Facebook’s Fairseq training over using the DGX-1 (which has half the number of GPUs, and a much more modest price tag, for the record):
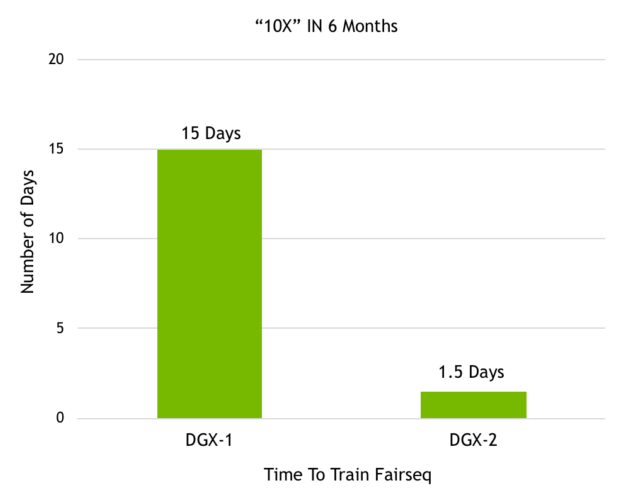
I feel like it’s important to note that these performance improvements are more important than they immediately appear, because while these gains dramatically impact today’s workloads, they’re effectively preempting even more complex workloads of the future.
Any performance gains in this space is hugely appreciated, especially when it means being given more performance after your purchase (a la TITAN Xp). If you have 16 GPUs chugging away on deep-learning workloads, and you suddenly receive a 10% performance gain, it’ll be as if you added another GPU-and-a-half to the mix. The difference here is that we’re not talking about just 10%, but significantly more. I don’t have an exact number since I don’t know specifics about the original V100 performance numbers, but it’s safe to say that these gains are in the double digits – or in other words, really significant.

Rob Williams
Rob founded Techgage in 2005 to be an 'Advocate of the consumer', focusing on fair reviews and keeping people apprised of news in the tech world. Catering to both enthusiasts and businesses alike; from desktop gaming to professional workstations, and all the supporting software.


